MyCat会玩吗?
https://mp.weixin.qq.com/s/RQfx1diIyMfcvdMCE5IdxQ一、MyCat背景
1、了解一下Mycat的由来:
- MyCat前身是阿里巴巴的Cobar,然而Cobar在开源一段时间后就没用维护了,阿里巴巴放弃了该项目,再加上Cobar在使用的过程中发现存在一些问题;
- 2013年国内一批开源软件爱好者对Cobar这个项目进行了改进,并命名为MyCat,这就是MyCat的诞生;
- MyCat是完全免费公开的,不属于任何商业公司;
- MyCat于2014年首次在上海的《中华架构师》大会上对外宣传,随后越来越多的项目采用了Mycat;
- 截止2015年11月,超过300个项目采用Mycat,涵盖银行、电信、电子商务、物流、移动应用、O2O的众多领域和公司;
2、MyCat介绍
- MyCat是一个开源数据库中间件,是一个实现了Mysql协议的数据库中间件服务器;
- 可以把MyCat看着一个数据库代理,用MySQL客户端工具和命令访问MyCat,而MyCat再使用MySQL原生(Native)协议与多个MySQL服务器通信;
- MyCat也可以用JDBC协议与大多主流数据库服务器通信(SQL server,Oracle,DB2,PostgreSQL)和NoSQL(MongoDB)通信,未来还会支持更多类型的存储;
- 一般MyCat主要用于代理MySQL数据库,虽然它也支持去访问其它类型的数据库;
- MyCat的默认端口是8066,一般可以使用常见的对象映射框架,比如MyBatis操作MyCat;
二、MyCat主要能做什么
1、读写分离
MyCat可以自动实现写数据时操作主数据库,读数据时操作从数据库,这样能有效地减轻数据库压力,也能减轻IO压力;
MyCat实现读写分离,当主出现故障后,会自动切换到另一个主上,从而提供高可用的数据库服务,前提数据库要部署多主多从的模式;
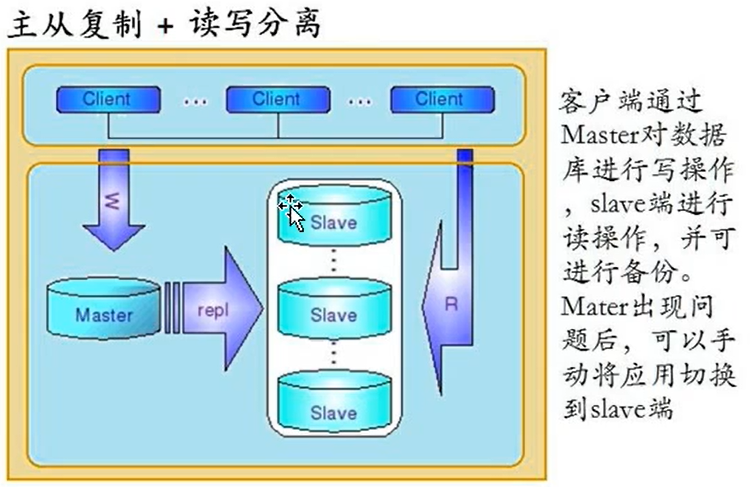
未用MyCat之间需要我们的java程序手动去确定是读是写,然后去对应上主库和从库,这个过程中如果出现了我是读数据,而操作到了主库,这样就会降低主库的效率;如果出现了我是写数据,而操作到了从库,会引起主从关系脱离,从而导致主从库数据不一致问题;
使用MyCat后,MyCat会分析sql语句,判断是读还是写操作,然后对应到主从库上,不会造成主从数据不一致问题;
读写分离前提就是主从复制,要始终保证主库和从库的数据的一致性;
2、水平拆分
- 根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库服务器上;
- 当一个表的数据达到几百万的时候,占用的磁盘高,且读性能大大降低,因此考虑水平拆分;
- 假设原来的一张表里有1000w数据,现在我们进行水平拆分到五个表中,这五个表在不同的服务器上,对应不同的URL,那么每个表里面的数据此时就只有200w条,读性能能明显提高,且在不同服务器上,对磁盘的占用也降低了;
- 但问题又出现了,为了保证五个服务器上的数据库高可用,那么是不是应该在每一个服务器上搞一个两主两从的数据库。因此直接从五张表变成了20张表;
- 由于表的数量增加,光靠java程序读和写是很有肯能造成数据不一致的。现在就把这20张表交给MyCat来管理,我们只需要向MyCat里面发送sql语句,其它的操作交给MyCat就可以了(比如说存取数据hash算法路由到对应的表,其中一个主库挂了,自动切换到另一个主库上)
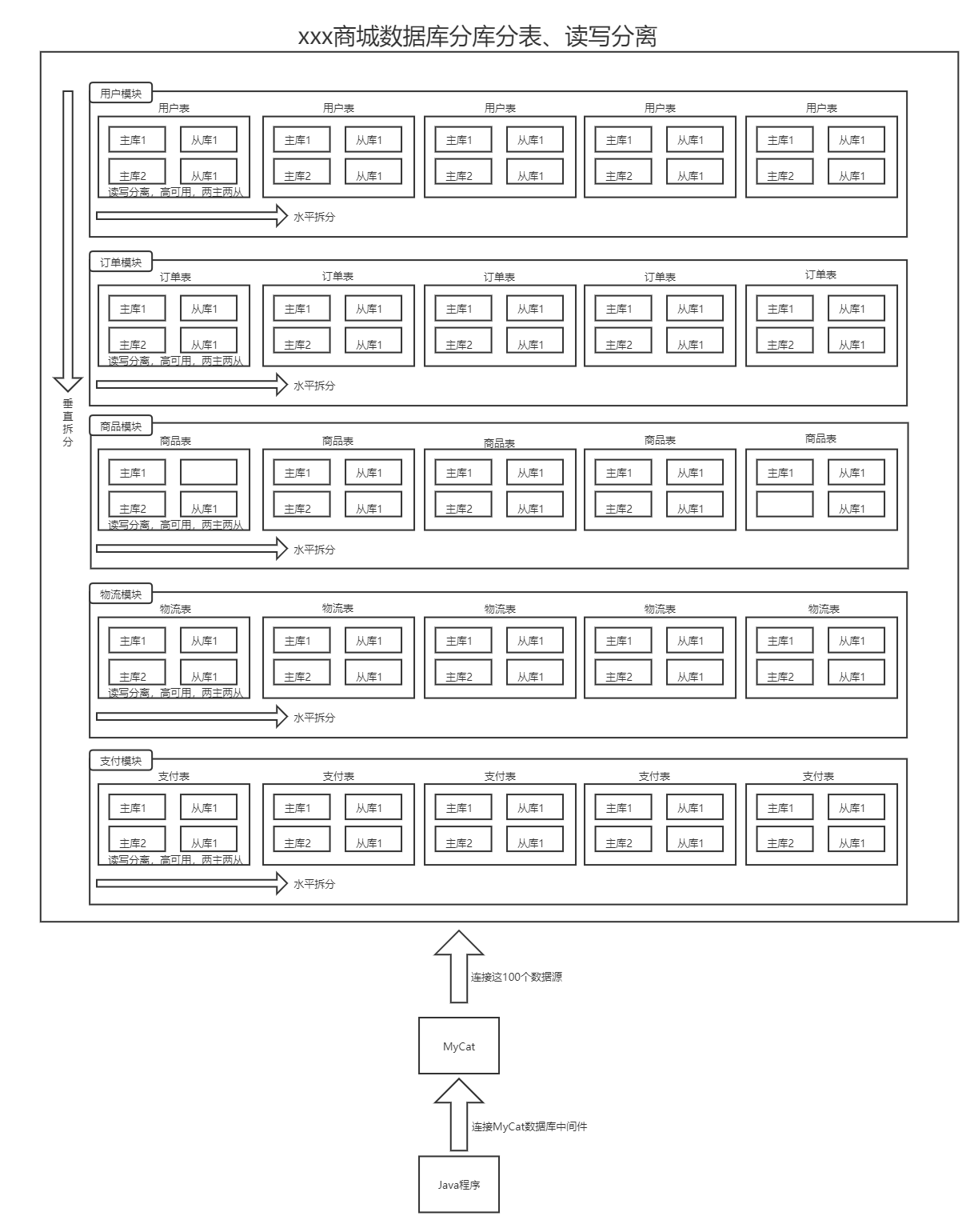
3、垂直拆分
- 按照不同的表拆分到不同的数据库服务器之上;
- 假如某个商城数据库里面有100张表,对应有用户模块、订单模块、商品模块、物流模块、支付模块,每个模块对应20张表,如果我们把这100张表都放在商品数据库这一个库里面,且商品数据库又在一个服务器上,存在的问题:
- 磁盘压力增加;
- 由于数据库连接池的最大连接数有上限,高并发场景下,有1000个人访问订单模块对应的表,只有1个人访问用户模块对应的表,那么此时就会形成IO竞争,会导致访问用户模块的线程等待,直到连接池里面有空闲的连接时,才会响应,因此用户体验变差;
- 综合第二点出现的情况,就需要采用垂直拆分。现在我们把用户模块、订单模块、商品模块、物流模块、支付模块分别放在5个不同的服务器上对应的数据库中,那么每个服务器上对应的数据库里面就只有20个表了,大大减小了磁盘的压力;
- 如果垂直拆分的这5个服务器中,有的表数据量很大,那么就要考虑水平拆分,这样一来对应的就是5x20,也就是100个服务器了,对应了100个数据源,这么多数据源都对应了不同的URL,如果就像之前开发那样去连接数据源,就需要写一百个。为了解决这个问题,MyCat就出现了,它是一个很好的数据库中间件,帮助我们拦截这些数据源,MyCat会根据我们要操作的数据库表来分析我们需要的表在那个库中,是读是写,然后进行连接;
- 通常我们使用垂直拆分以后都是需要程序员分组独立开发,对应到不同的模块,因此基本上不会跨模板访问数据库表;开发一个模块的程序员不会知道另一个模块的账号和密码,其它模块的程序员也不会允许我们这么做,因此实际工作中出现跨模块访问都是使用对方提供的接口来进行访问的
三、安装MyCat
1、在Linux上搭建MyCat
1、下载后缀名为 .tar.gz 的压缩包,上传到Linux服务器上
1)进入/tmp目录下 cd /tmp 2)wget下载lrzsz安装包 wget http://www.ohse.de/uwe/releases/lrzsz-0.12.20.tar.gz 注:输入wget,如果提示未找到命令,则需要yum install wget进行安装wget命令2、执行解压命令到:usr/local 位置
tar -zxvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz -C /usr/local/3、解压后进入 usr/local 会多出来个MyCat文件
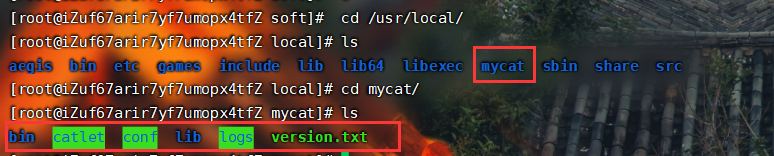
4、了解以下各文件的作用:
bin:可执行文件的命令目录,bin下面的MyCat文件是启动命令,后面跟start为启动,跟stop为关闭
conf:配置文件目录,重点关注里面的schema.xml和server.xml,需要用到,把这两个文件次下载到window系统上。命令:sz schema.xml 和 sz server.xml,前提要安装sz下载命令,参考文档;
rz:上传命令,sz:下载命令,rz和sz软链接的创建参考文档
rule.xml:是一些拆分规则
logs:存放一些日志信息,MyCat不会报错,一切报错查看logs里面的日志文件
5、了解一些MyCat的常用操作命令:
启动命令:切换到MyCat的bin(cd /usr/local/mycat/bin)目录下执行:
./mycat start关闭命令:
./mycat stopMyCat命令行:
MyCat默认端口是:8066
登录MyCat命令行,使用mysql的命令行工具来操作(需要切换到mysql的bin目录下执行该命令):
./mysql -umycat -p -P8066 -h127.0.01


2、MyCat配置文件解读
server.xml 和 schema.xml
https://blog.csdn.net/cold___play/article/details/107489340推荐一个xml编辑器:foxe_CHS.exe 下载地址
https://pc.qq.com/detail/2/detail_10202.html
1、server.xml:该文件属于MyCat的服务配置
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。
在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="useHandshakeV10">1</property>
<property name="removeGraveAccent">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">1</property> <!--关注点1:这个是主键生成策略,表明MyCat的主键单调递增(0-本地文件,1-数据库,2-时间戳)-->
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
INSERT INTO `travelrecord` (`id`,user_id) VALUES ('next value for MYCATSEQ_GLOBAL',"xxx");
-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
<!--如果为0的话,涉及多个DataNode的catlet任务不会跨线程执行-->
<property name="parallExecute">0</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="mycat" defaultAccount="true"><!--默认name的值是root,为了和mysql区分这里改为mycat-->
<property name="password">123456</property>
<property name="schemas">mycatdb</property><!--逻辑库,不是真实存在的,一个虚拟的库,属于MyCat模拟出来的;默认是TESTDNB,这里改为mycatdb,好区分-->
<property name="defaultSchema">mycatdb</property><!--默认数据库,默认是TESTDNB,这里改为mycatdb,好区分-->
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" > 四个数字对应到对这个数据库的增删改查操作,0表示没有权限,1表示有权限
<table name="tb01" dml="0000"></table> 0000表示对TESTDB这个数据库的表tb01没有增删改查权限操作
<table name="tb02" dml="1111"></table> 1111表示对TESTDB这个数据库的表tb01有增删改查权限操作
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">mycatdb</property>
<property name="readOnly">true</property><!--表明user登录的话,只能读数据不能写数据-->
<property name="defaultSchema">mycatdb</property>
</user>
</mycat:server>2、schema.xml:属于MyCat配置文件
主要由三部分主城:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--name要和server.xml里面配置的逻辑库名相同,checkSQLschema检查sql语法的标准,通常为false,sqlMaxLimit表示每个sql语句最多返回100条数据-->
<schema name="mycatdb" checkSQLschema="false" sqlMaxLimit="100" randomDataNode="dn1">
<!-- auto sharding by id (long) -->
<!--splitTableNames 启用<table name 属性使用逗号分割配置多个表,即多个表使用这个配置;不需要水平拆分是不用配置这个的-->
<table name="travelrecord,address" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<!--dataNode表示数据节点,配置物理库(MySQL真实创建数据库)的名称;
name对应到标签<schema>里面定义好的,名字可以随便起,但一定要对应‘
dataHost名字可以随便起,但要和标签<dataHost>里面的相对应;
database表示物理库名称
-->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<!--name表示主机位置,用来配置读写分离(当数据库节点有了主从复制时);
maxCon和minCon表示数据库连接池的最大和最小连接数量;
balance表示负载均衡策略;
dbType指定mycat需要连接数据库的类型;
dbDriver表示数据库的驱动类型(native表示原生驱动,注:只有mysql用native,其它数据库采用jdbc);
switchType表示配置故障切换类型(1-select user() ,2-show slave status ,3 -show status like 'wsrep%'),它会配合标签<hearbeat>,即心跳机制;
slaveThreshold表示主节点配置从节点的数量,最多配置100个;
<heartbeat>表明心跳语句,定器判断服务器是否好用,是否有故障,如果宕机了,就不在向该服务器发请求了,需要配合switchType来使用,不同switchType有不同的心跳语句;
<writeHost>表示配置读写页,写数据就配置主服务器(数据库),读数据就配置从服务器(数据库);
<readHost>配置写节点,配置好后,我们读数据,mycat就会找到读节点,通过账号和密码进行连接,然后把sql语句转发给读节点
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts 可以配置多个主库 -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!--can have multi read hosts 每个主库可以配置多个从库-->
<readHost host="hosts1" url="192.168.1.103:3306" user="root" password="xxx"/ >
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!-- 下面是配置oracle的样式
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>四、读写分离
1、读写分离配置
操作步骤:
- 配置好schema.xml和server.xml文件
- 覆盖掉config下的文件
- 进入bin目录,输入:./mycat start 启动mycat
- ps -ef | grep mycat 命令查看mycat运行情况
关于server.xml配置
配置逻辑表的名字和秘密
可以配置多个
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://io.mycat/"> <system> <property name="nonePasswordLogin">0</property> <property name="ignoreUnknownCommand">0</property> <property name="useHandshakeV10">1</property> <property name="removeGraveAccent">1</property> <property name="useSqlStat">0</property> <property name="useGlobleTableCheck">0</property> <property name="sqlExecuteTimeout">300</property> <property name="sequnceHandlerType">2</property> <property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property> <property name="subqueryRelationshipCheck">false</property> <property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property> <property name="processorBufferPoolType">0</property> <property name="handleDistributedTransactions">0</property> <property name="useOffHeapForMerge">0</property> <property name="memoryPageSize">64k</property> <property name="spillsFileBufferSize">1k</property> <property name="useStreamOutput">0</property> <property name="systemReserveMemorySize">384m</property> <property name="useZKSwitch">false</property> <property name="strictTxIsolation">false</property> <property name="useZKSwitch">true</property> <property name="parallExecute">0</property> </system> <user name="mycat" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">mycatdb</property> <property name="defaultSchema">mycatdb</property> </user> <user name="user"> <property name="password">user</property> <property name="schemas">mycatdb</property> <property name="readOnly">true</property> <property name="defaultSchema">mycatdb</property> </user> </mycat:server>
schema.xml配置
- 读写分离,配置两主两从,高可用
- 预先安装四个mysql,指定不同端口,这里用的docker
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycatdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="workdb" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3307" user="root" password="root">
<readHost host="hostS1" url="localhost:3308" user="root" password="root"/ >
</writeHost>
<writeHost host="hostM2" url="localhost:3309" user="root" password="root">
<readHost host="hostS2" url="localhost:3310" user="root" password="root"/ >
</writeHost>
</dataHost>
</mycat:schema>2、读写分离测试
五、java代码连接MyCat
六、水平拆分
1、水平拆分
2、水平拆分测试
七、垂直拆分
八、MyCat主键生成策略
九、MyCat总结
十、何时分库分表
| 并发量 / 数据量 | 分库 | 分表 |
|---|---|---|
| 并发量大和数据量小 | 分 | 不分 |
| 并发量小和数据量大 | 不分 | 分 |
| 并发量大和数据量大 | 分 | 分 |



