es进阶
一、结构化搜索
1、term filter搜索数据
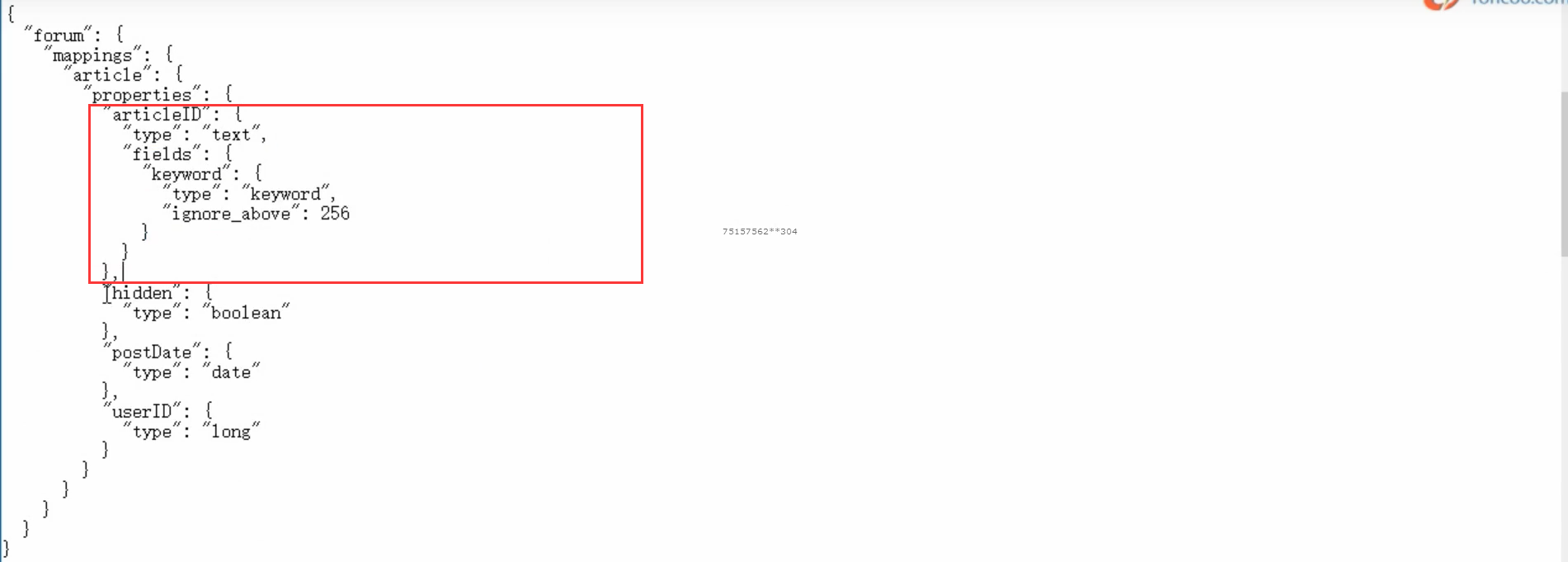
es版本5.2以后,type=text,默认会有两个field,一个是field本身,比如articleID,是支持分词的;还有一个就是field.keyword,它默认是不支持分词的,会最多保留256个字符
term filter注意点:
对搜索文本不分词,直接拿去倒排索引中匹配,你输入的是什么,就去匹配什么;
因此在搜索type=text的字段时,使用feild本身是搜索不到内容的,因为已经对field本身这种字段进行了分词;而应该采用field.keyword这种字段进行搜索,它不会进行分词,因此能搜索到相应结果;
所以term filter,对text过滤,可以考虑使用内置的field.keyword来进行匹配,但默认只保留256个字符。所以尽可能自己去手动建立索引,指定not_analyzed,但在新版本的es中,可以不指定not_analyzed了,将type=word即可。

2、_filter执行原理
_filter执行原理深度剖析(bitset机制与caching机制)
bitset机制:
一个二进制数组;
使用找到的doc list,构建一个bitset二进制数组,数组的每个元素都是0或1,用来表示一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0;

bitset机制好处是尽可能用简单的数据结构去实现复杂的功能,可以节省内存的空间,来提升性能;
对于过滤条件比较多的_search,每个条件都对应一个bitset。在查找满足所有条件的doc时,会遍历每个过滤条件对应的bitset,但会先遍历比较稀疏的bitset,就可以先过滤尽可能多的数据,提升性能
caching机制:
- 缓存过滤条件达到一定次数的bitset;
- 在最近的256个query中,超过了一定次数的过滤条件,缓存其bitset在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,反复生成bitset了,可以大幅度提升性能;
- 如果doc有新增或修改,那么cached bitset会自动更新,当有相同的filter条件时,会直接使用这个过滤条件对应的cached bitset;
filter和query的对比:
- filter大部分情况下,在query之前执行,先尽可能过滤掉尽可能多的数据;
- query会计算doc对搜索条件的relevance score,还会根据这个socre去排序,性能低;
- filter只是简单过滤出想要的数据,不会计算relevance score,也不会排序,性能高,过滤大部分数据;
3、bool组合多个filter条件
bool下面可以跟:must,must_not,should等过滤条件,分别表示:必须匹配、必须不匹配、应该匹配;可以对应到sql中的==、!=、or;或者说对应:满足所有条件的过滤、不满足所有条件的过滤、满足条件中的1个的过滤。

bool还可以嵌套:

4、terms使用
使用terms搜索多个值,以及多值搜索结果优化


上面的搜索包含java的对应的文档记录,现在优化只包含java的文档记录,添加一个字段tag_cnt记录tag包含的条数,则优化后的请求是这样的

5、range filter范围过滤
range类似于sql中的算数运算符或者between
数值

日期

二、深度探秘搜索技术
1、手动控制全文检索精确度
全文检索match query。
如果检索的字段是not_analyzed类型(type=keyword),那么match query也相于term query

通过and关键字实现搜索结果精确控制

通过minimum_should_match指定文档记录中必须匹配多少个关键字才能结果返回



2、term+bool底层原理
term+bool实现multiword搜索底层原理解析



3、基于boost的细粒度搜索条件权重控制
boost的作用:
- 加大某个搜索条件的权重
- 权重越大的搜索条件所对应的relevance score就越高,就会优先返回作为结果

4、多shard场景下relevance score不准确问题
当一个索引有多个分片的时候,搜索结果可能会不准确
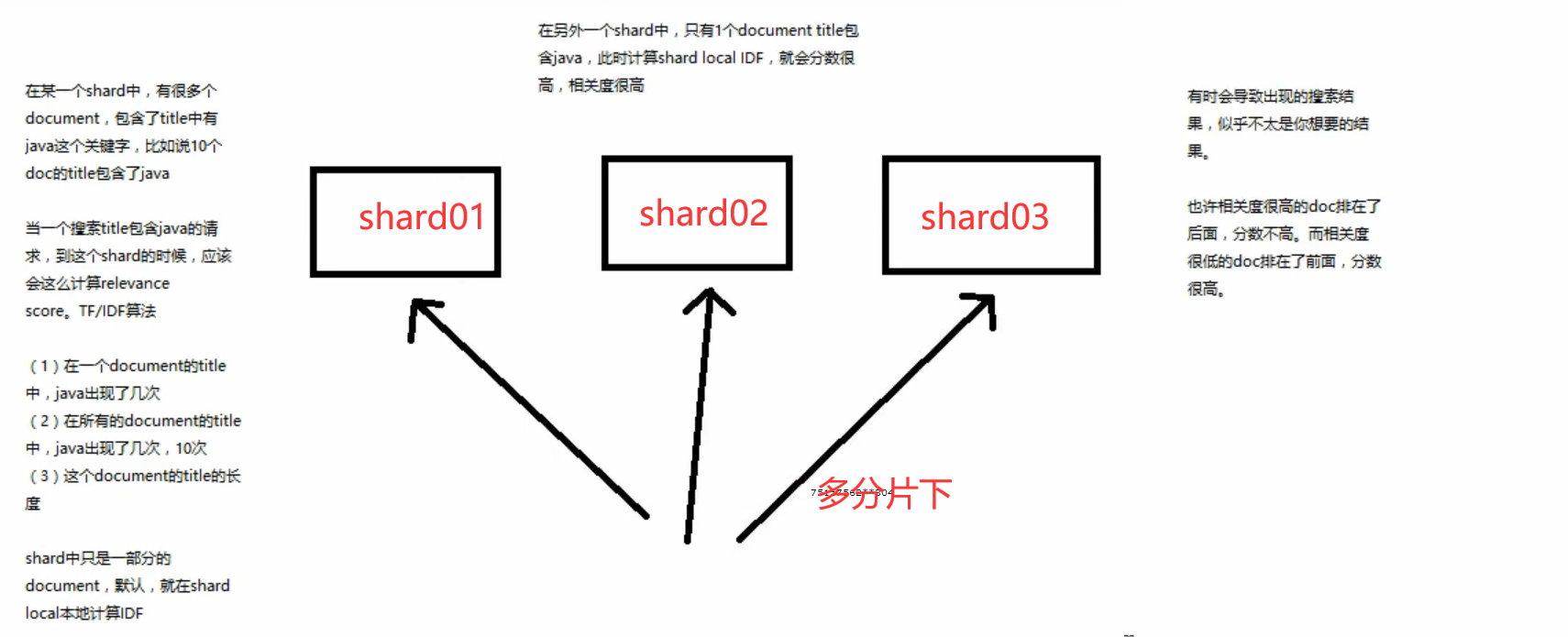
如何解决

5、基于dis_max实现best fields策略进行多字段搜索
批量加入字段通过_bulk

多字段搜索

best fields策略
dis_max只会考虑把多条匹配语句中分数最高的拿来做比较

6、基于tie_breaker参数优化dis_max搜索效果

案例分析

tie_breaker解决上方案例中dis_max的缺点(tie_breaker取值在0~1)
使用tie_breaker将其它query分数也考虑进去

7、基于multi_match语法实现dis_max和tie_braker

上面的查询请求写法直接通过multi_match(dis_max直接通过type指定为best_fields)

8、基于multi_match+most fields策略进行multi_field搜索
best-fields对比most fields :
- 前者主要是说某一个field匹配尽可能多的关键字的doc优先返回回来
- 后者主要是说尽可能返回更多field匹配到某个关键字的doc优先返回回来

指定分词器

multi_match进行搜索(type指定为most_fields即可)

best-fields对比most fields

9、使用most_fields策略进行cross-fields 搜索弊端解析
关于cross-fields

定义文档

执行搜索

结果分析:
- 按道理doc5应该排第一,包含了 Peter Smith,但结果doc2排到了第一;

弊端分析

10、使用copy_to定制组合field解决cross-fields搜索弊端
copy_to原理

copy_to语法(将多个字段值拷贝到一个字段中,并建立倒排索引)

添加doc

执行查询请求

结果分析




