你真会玩索引?
一、mysql索引的创建
1、什么是索引?
索引类似图书中的目录,可以利用索引快速查找到表的记录;
索引需要额外的磁盘空间来存放,每次更新数据时系统都会拿出额外的时间来更新索引;
索引应该建立在重复率较低的列上,最好是唯一列;
索引应该建立在内容比较少的列上,最好是数字列;
综合上注意:
- 索引应该建在经常作为查询条件的列上,可以提高查询效率;
- 不要在频繁修改的列上创建索引;
- 索引不要建立得特别多;
2、索引的创建
1、索引的创建语法
方法一:create [unique] index 索引名 on 表名(列名1,列名2,…列名n)
方法二:alter table 表名 add [unique] index 索引名(列名1,列名2,…列名n)
需注意:
- unique是可选的,添加以后表示当前列是唯一索引;
- 可以同时为多个列建立索引,称为复合索引,但是建立好复合索引以后,只有这些列同时出现在where后面索引才会起作用,不推荐使用复合索引;
- 索引名字除在删除索引时有用以外其它时候没有作用,但不能重复;
2、实操
这里用的是Navicat工具
步骤:
随意点击一个表,右键点击设计表,点击导航栏上的索引,跳出如下界面
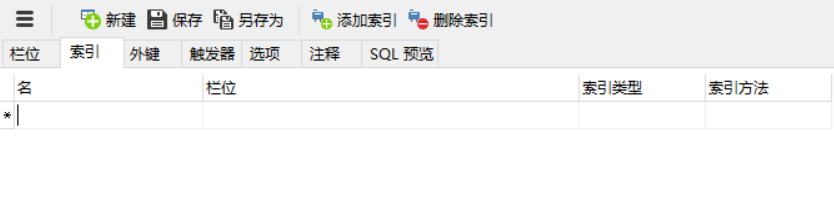
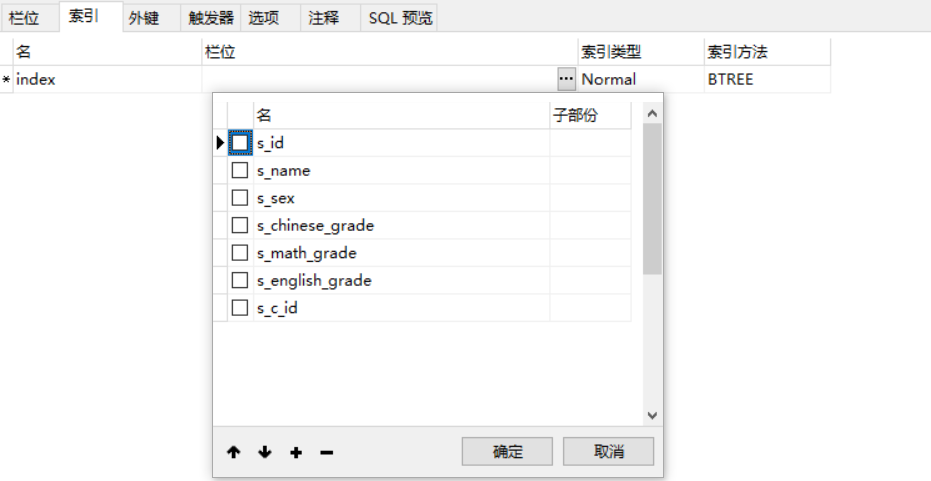
起个索引名,栏位即选择创建索引的字段,索引类型选择默认的Normal,索引方法选择BTREE
3、删除索引语法
方法一:DROP INDEX 索引名 on 表名
方法二:ALTER TABLE 表名 DROP INDEX 索引名
方法三:用工具
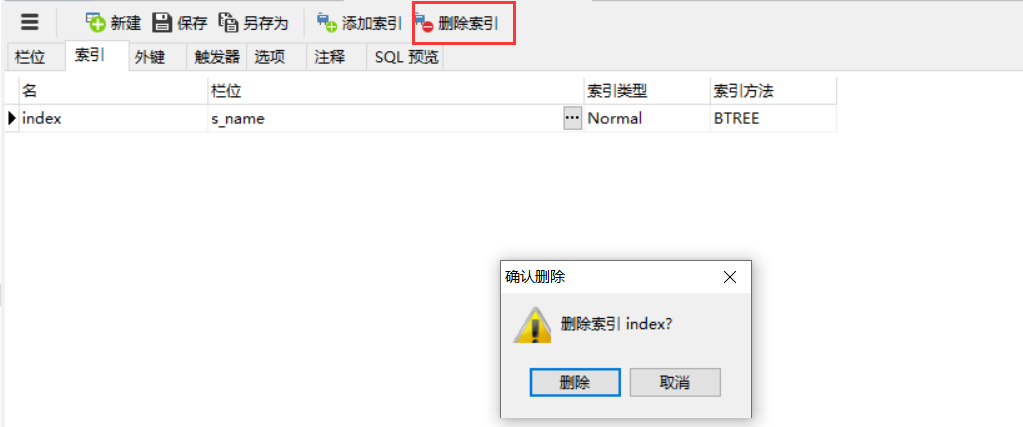
3、索引的使用
通过在sql语句前添加EXPLAIN(SQL的执行计划)来查看所建立索引的执行情况,通过type来明了是否使用了索引。
type取值(除all和index外都用到了索引):
all——没有使用到索引,表示全文检索,即扫描全表后返回结果查询;
index——没有使用到索引,表示索引全文检索,即扫描所有索引后返回结果查询;
ref——使用到索引,表示精准获取某个数据,它会直接到索引中去获取数据;
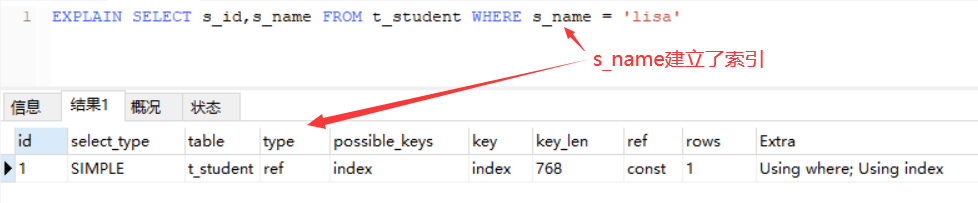
range——使用到索引,表示某个范围类使用索引(即where后面使用了运算符,且查询列是索引列,则type就会为range),只扫描了部分索引
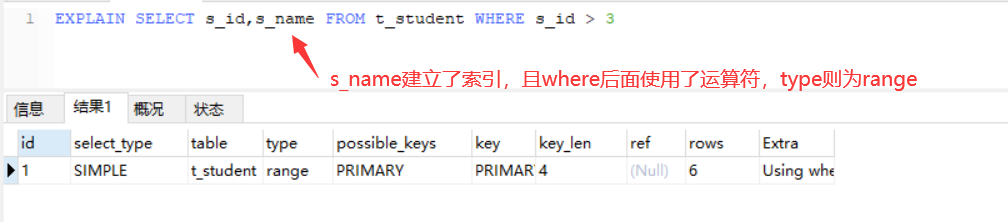
综上注意:
- 主键、唯一约束、外键默认都是带有索引的 ,因此它们查询速度快。
二、分析索引
1、索引的本质
- 索引是帮助mysql高效获取数据的*排好序的数据结构*
- 索引的数据结构:
- 二叉树
- 红黑树
- Hash表
- B-Tree
我们知道mysql索引支持Hash和B+Tree两种数据结构,但为什么平时开发中都选择B-Tree呢?
1、Hash结构就是通过给定的主键索引,通过hash算法计算出具体某一位置,然后获取到数据,效率相当的快,的确Hash结构很适合于不是范围查找的sql语句,但一旦是范围查找,hash这种结构就懵逼了;
2、首先要明白B+Tree在树深度确定的时候,就分为叶子节点和非叶子节点,叶子节点存储索引和数据,非叶子节点存储索引,从左到右索引的大小关系都是递增的,因此在叶子节点间,从左到右就有一个指针指向下一个叶子节点(相当于下一个节点的存储地址),因此在范围查找的时候,直接通过这个指针我们就可以把我们想要的数据返回回去,范围查找远远高于Hash这种结构。注意:这里指的是B+Tree,B-Tree叶子节点之间没有指针指向下一个节点,下面会阐述它们两者的区别;
2、红黑树
二叉树结构
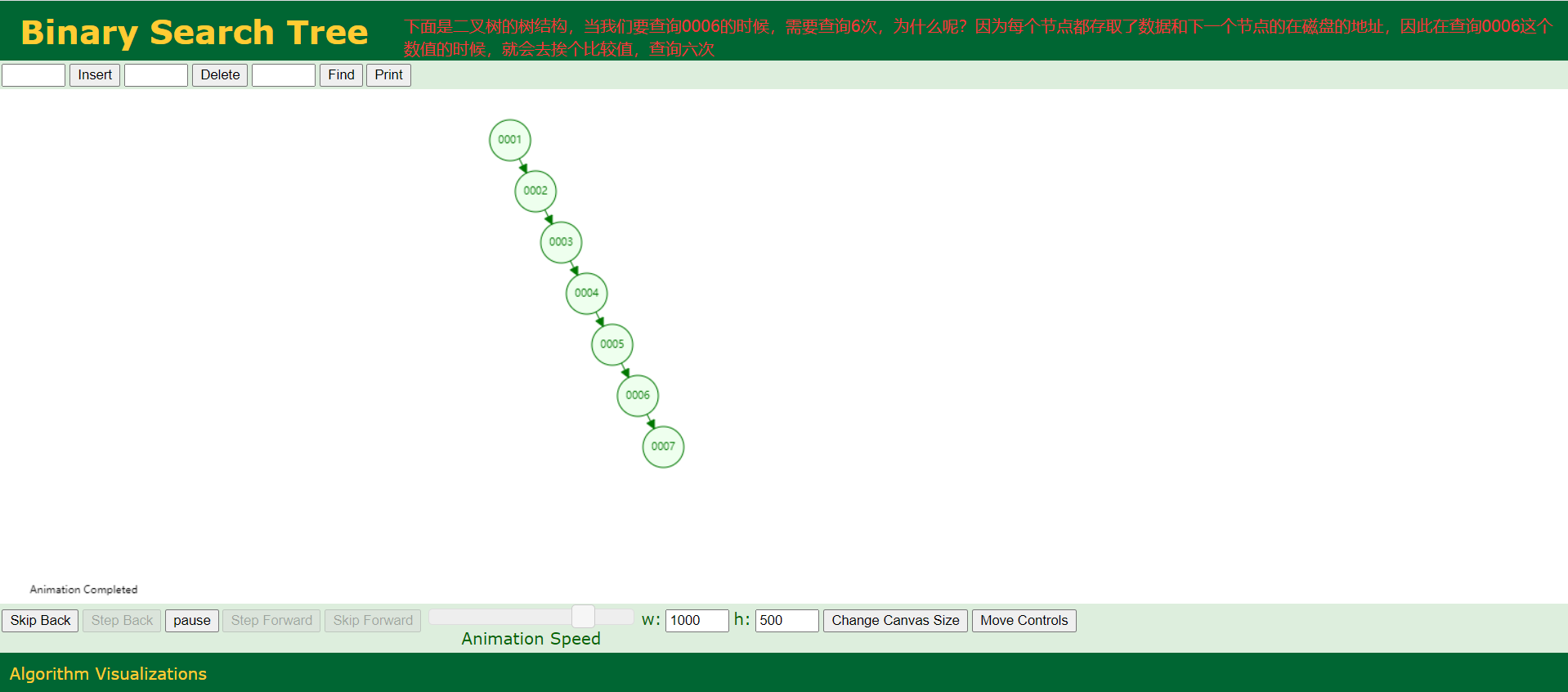
红黑树结构(平衡二叉树)
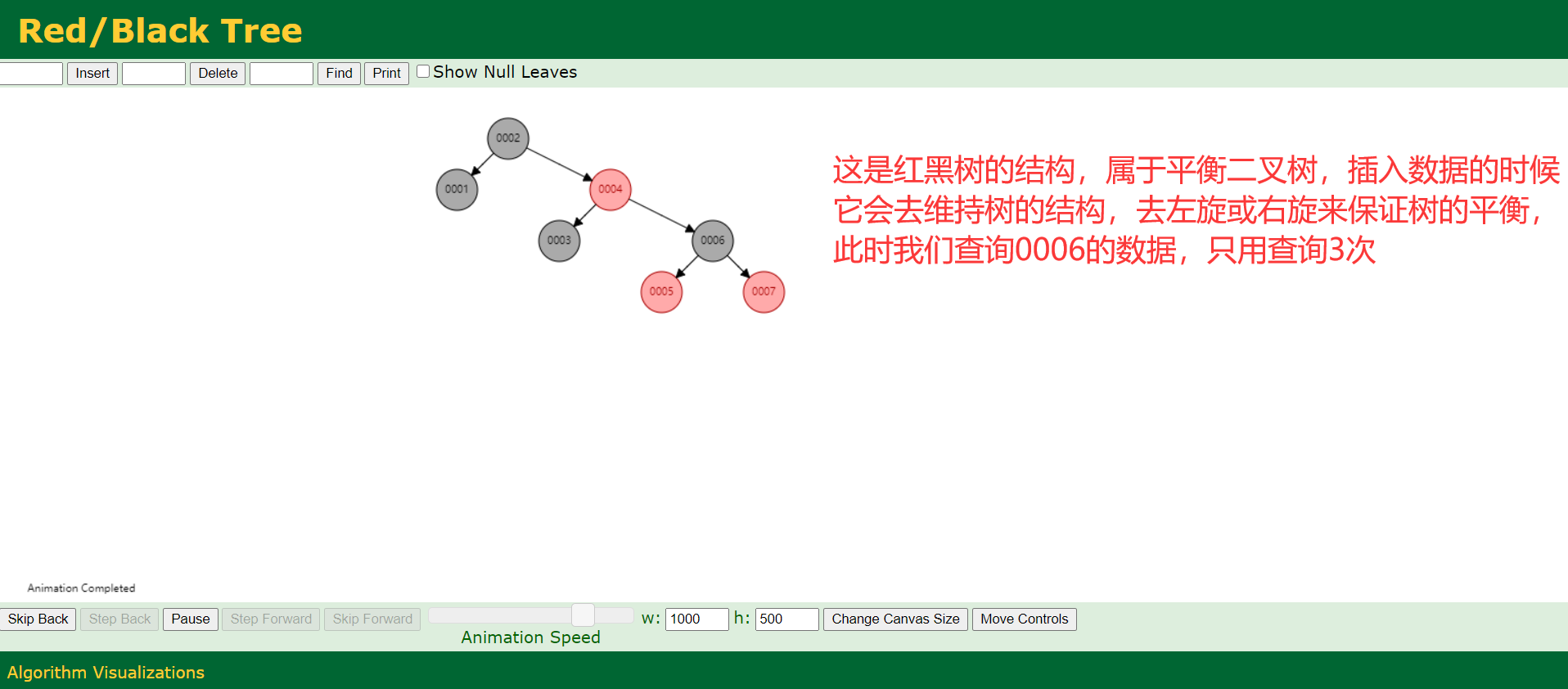
3、B+tree结构
为什么要有B+tree?
- 如果像二叉树黑红黑树那样,一直向里面插数据,那么树结构的高度会越来越高,假如要查询一个数据为1000的数据,同样会查询很多次,才能找到其在磁盘上的位置;
- 为了解决二叉树和红黑树,这种在纵向无线扩展的缺点,就有了B+tree;
- B+tree恰好相反,它是在横向扩展,保证了纵向了高度不变后,要求横向上的节点(索引)从左到右递增排列,且所有索引不重复
知道B+tree前,先来了解一下B-tree的结构
B-tree的结构特点:
叶节点具有相同的深度,叶节点的指针为空;
所有的索引元素不重复;
节点中的数据索引从左到右递增排列;
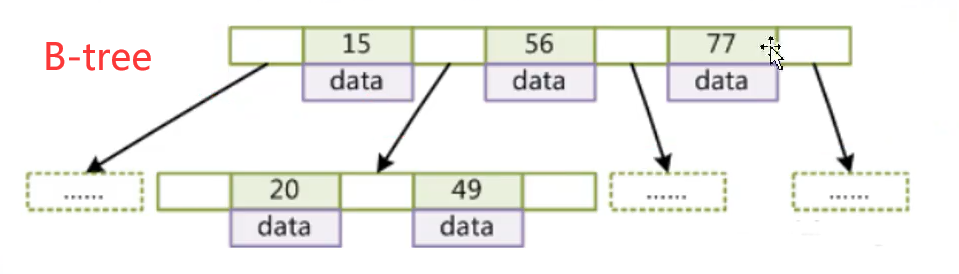
B+tree的结构
B+tree的结构特点:
非叶子节点不存储数据,只存储索引,因此可以放更多的索引
叶子节点包含所有索引字段;
叶子节点用指针连接,提高区间访问性能;
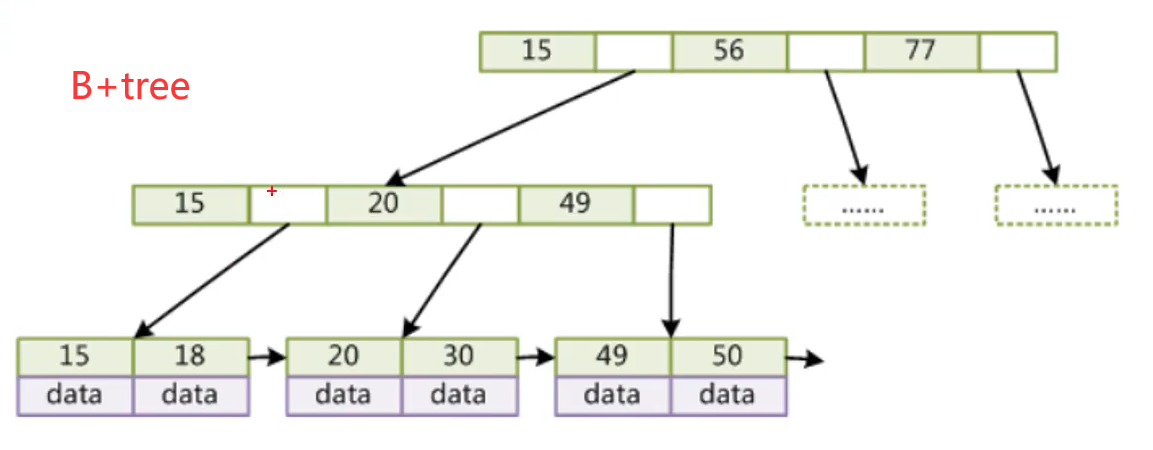
4、索引如何支撑千万级别的快速查询
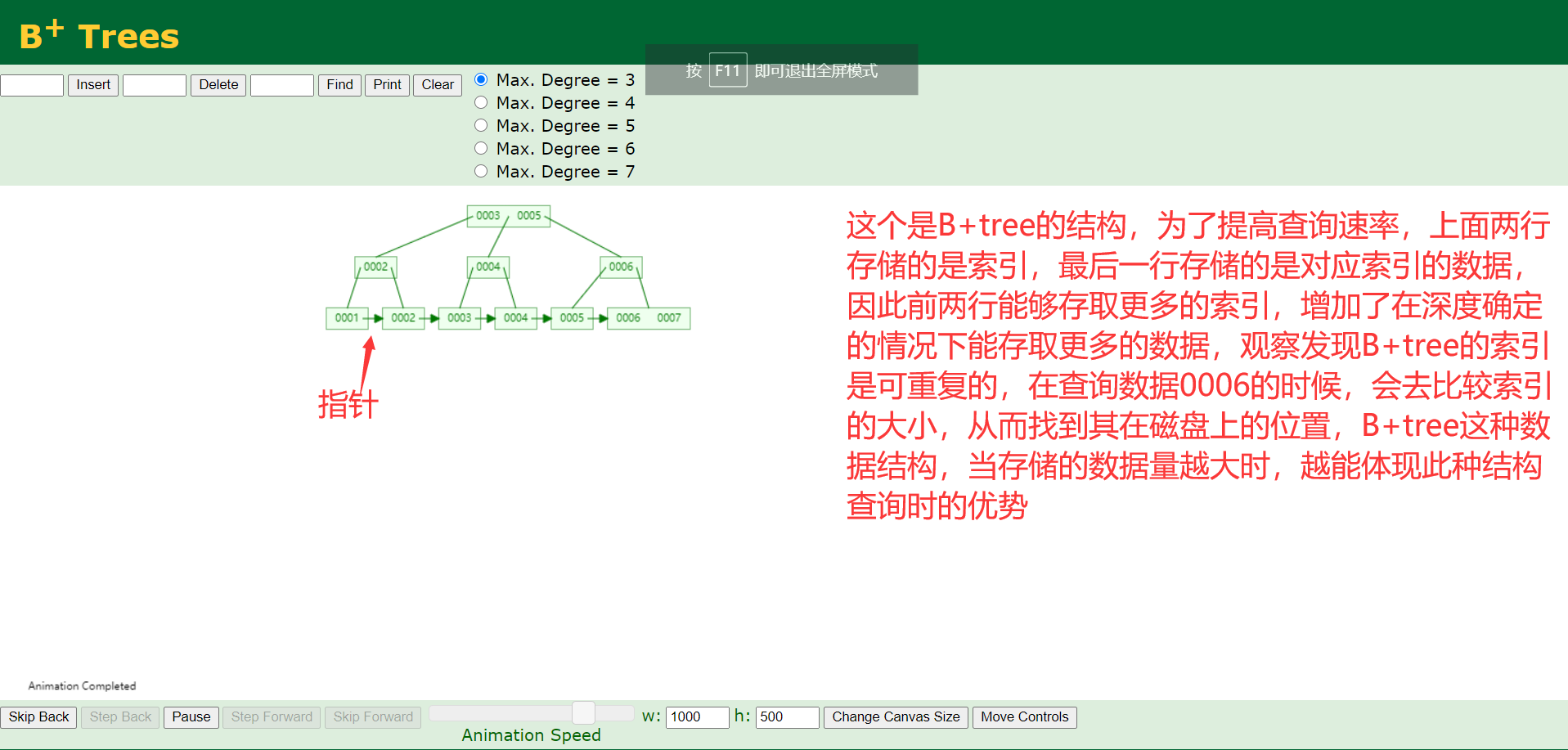
5、myisam存储引擎索引
myisam索引是非聚集索引:
myisam的索引文件和数据文件是分离的?
首先明白存储引擎是来形容表的,而不是数据库;

表里面的数据存储是在磁盘上面的;
myisam存储在磁盘上对应三个文件(”xxx.frm”,”xxx.MYD”,”xxx.MYI”)
- 以.frm后缀结尾的文件表示: 表结构定义的一些数据
- 以.MYD后缀结尾的文件表示: 存储的是myisam的数据
- 以.MYI后缀结尾的文件表示: 存储的是myisam的索引数据,比如主键
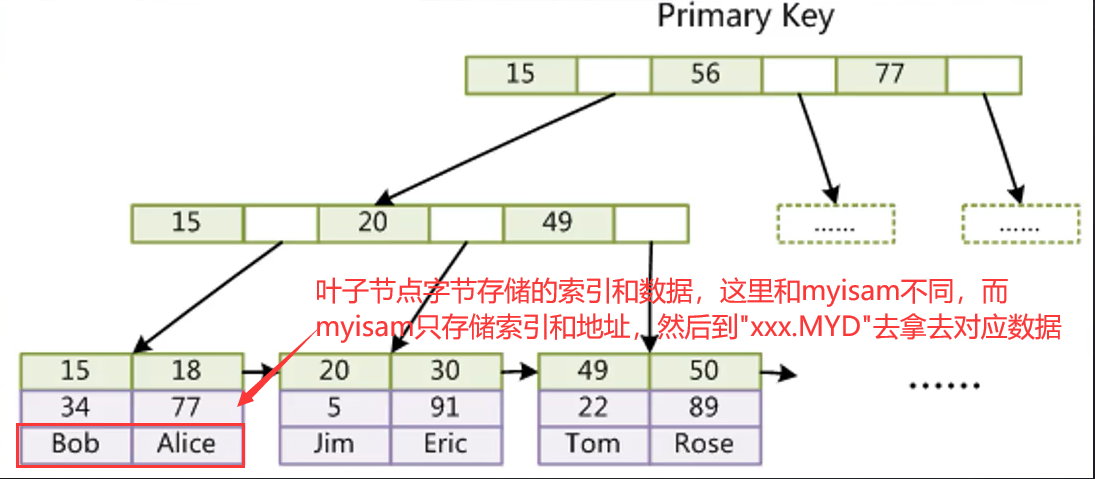
一张图搞清myisam索引结构;
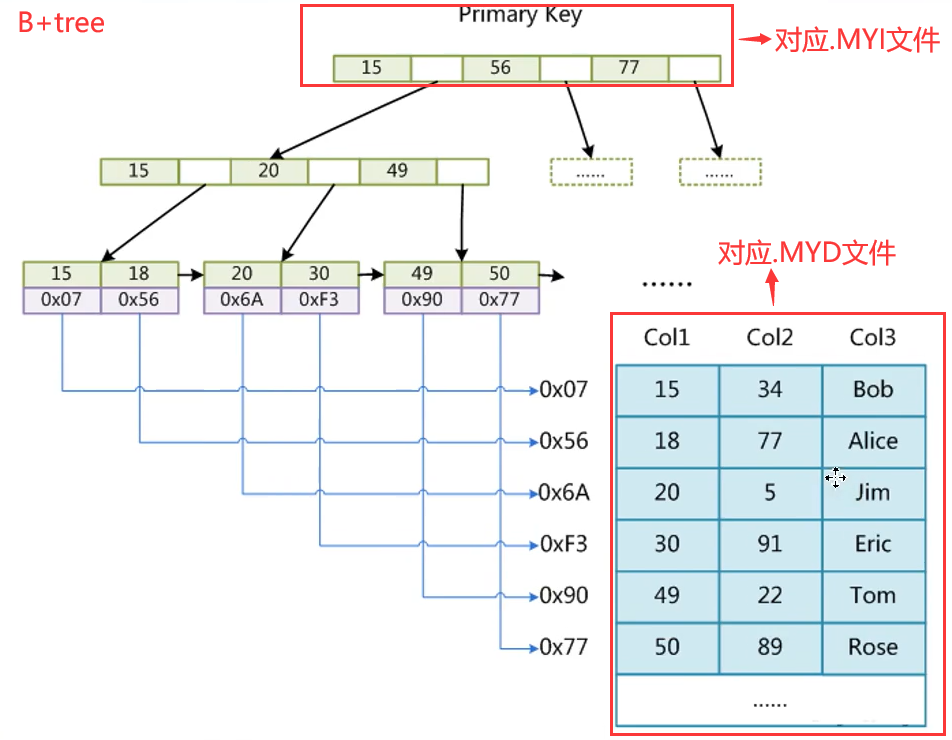
图片分析:
- 主键自带索引,因此无需创建索引在.MDI文件里面就有主键这些数据;
- 通常我们选择字段建立索引的时候选择的数据结构也是B+tree;
- 来个案列分析:假如Col1位主键列,现在要查询Col1=49这条记录的书籍,分析一下执行过程?
- 首先判断Col1这个字段是否创建索引,发现Col1是主键是索引,那么按照索引的方式来查询这条数据;
- 非叶子节点比较索引的大小,从而在叶子节点找到对应数据在磁盘的存储位置;
- 然后通这个位置到.MYD这个数据文件里面去找到要查询的记录;
6、innodb存储引擎索引

innodb索引是聚集索引:
表数据文件本身就是按B+tree组织的一个结构文件;
- innodb存储在磁盘上对应二个文件(”xxx.frm”,”xxx.ibd”)
- “xxx.frm”表示定义表结构的数据,”xxx.ibd”表示索引数据和存储的数据,相比myisam而言,”xxx.ibd”就是”xxx.MYD”,”xxx.MYI”的整合
聚集索引-叶子节点包含了完整的数据记录;
#什么是聚集索引?
首先明白innodb的主键索引就是聚集索引;由上面可晓而知,索引和数据一起存储就是聚集索引;innodb通过索引查询的时候,只需要过滤”xxx.ibd”文件,就能获取我们想要的数据
#什么是非聚集索引?
首先明白myisam的主键索引就是非聚集索引;由上面可晓而知,索引和数据分开存储就是非聚集索引;myisam在通过索引查询的时候,除了要过滤”xxx.MYI”文件,还要过滤”xxx.MYD”,才能获得我们想要的数据
为什么innodb表必须有主键,并且使用整型的自增主键;
1、通过主键来维持聚集索引这种结构,即使你设计表结构时候没有建立主键,innodb也会默认给你搞一个自增的整型的主键来维持聚集索引这种结构,所以不可能没有主键;
2、为什么主键选择整型的自增主键而不选用UUID这样的字符串作为主键,由上面我们知道,在通过索引去查询数据的时候,索引之间会相互比较,来获取索引的具体位置,如果选用UUID这样的字符串作为主键在查询的时候,比较的效率会特别慢(先转换成ASCII码才会去比较)。因此从效率上考虑,整型自增的主键效率更高;
3、UUID字符串是一个长字符串,所占用的磁盘空间远远大于整型。因此从磁盘空间上考虑,在数据量达到几百万时候,整型自增主键更加,相比UUID占用磁盘少;
4、为啥又要是自增的整型?首先明在B+Tree这种数据结构中从左到右索引递增,用递增的整型的好处就是,我们添加数据的时候就会在最右面添加索引数据;而如果是UUID这种随机的字符串通过计算得到的ASCLL码,再去添加数据,这个索引就不会遵循,在最右面添加索引数据,很可能在叶子节点中的某一个位置进行添加,就会导致叶子节点分裂和做树平衡,产生性能上的开销。因此在添加数据的时候,采用整型自增作为主键能够降低性能开销,在大批量插入数据时候,增快插入速率;
为什么非主键索引结构叶子节点存储的是主键值(一直性和节省存储空间)
7、mysql索引优化
#搞清联合索引?
实际上开发的时候采用的都是联合索引比较多,联合索引就是把几个字段放在一起来作为索引,增大查询效率;
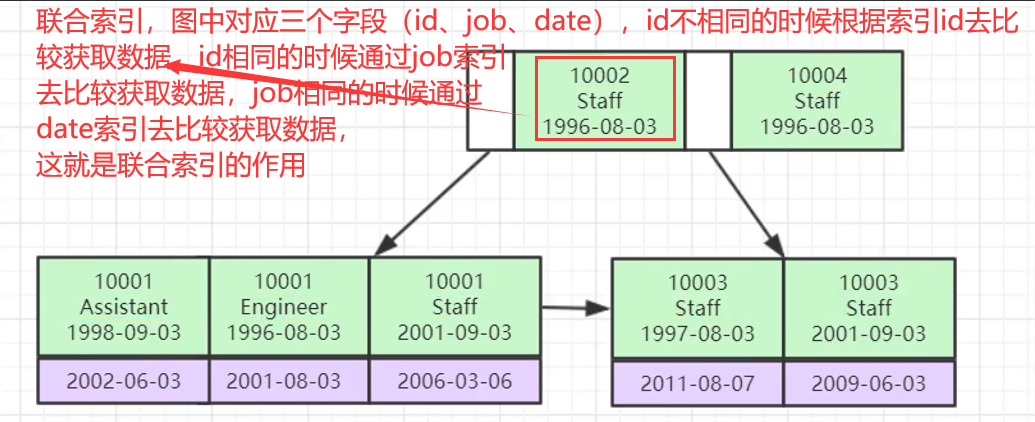
案列分析
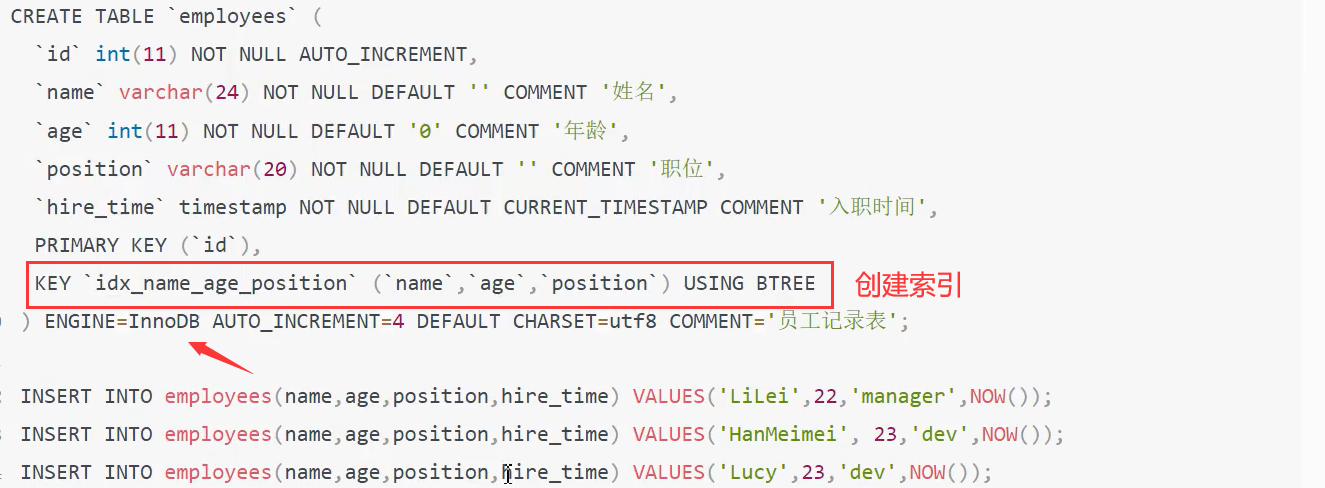
1、创建一个表,指定三个字段,构成联合索引
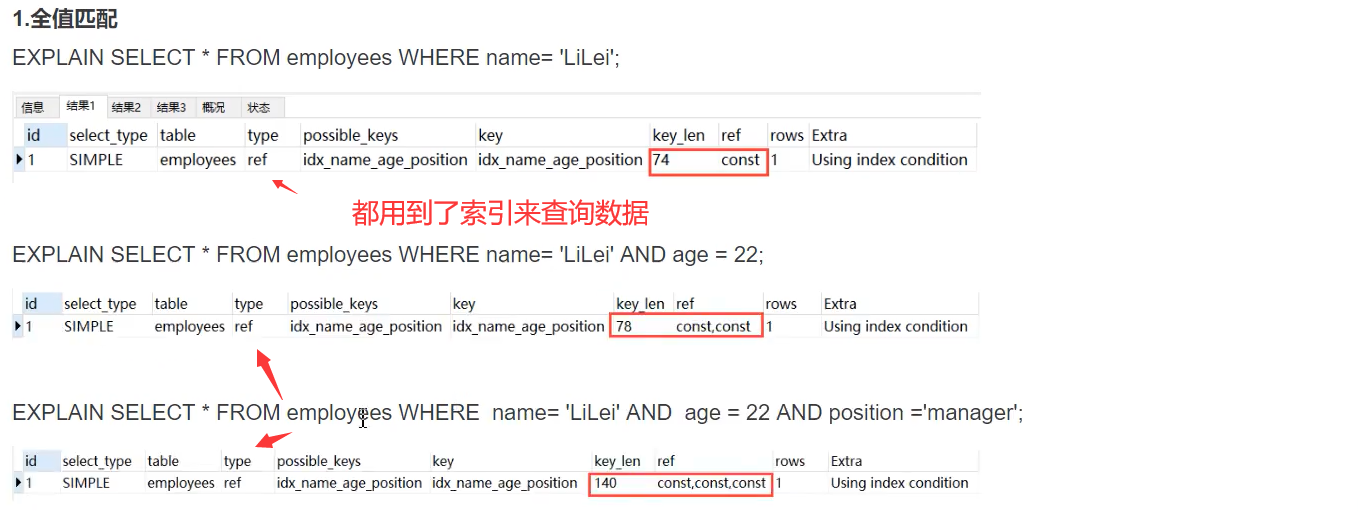
2、权值匹配
3、最左前缀法则

4、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
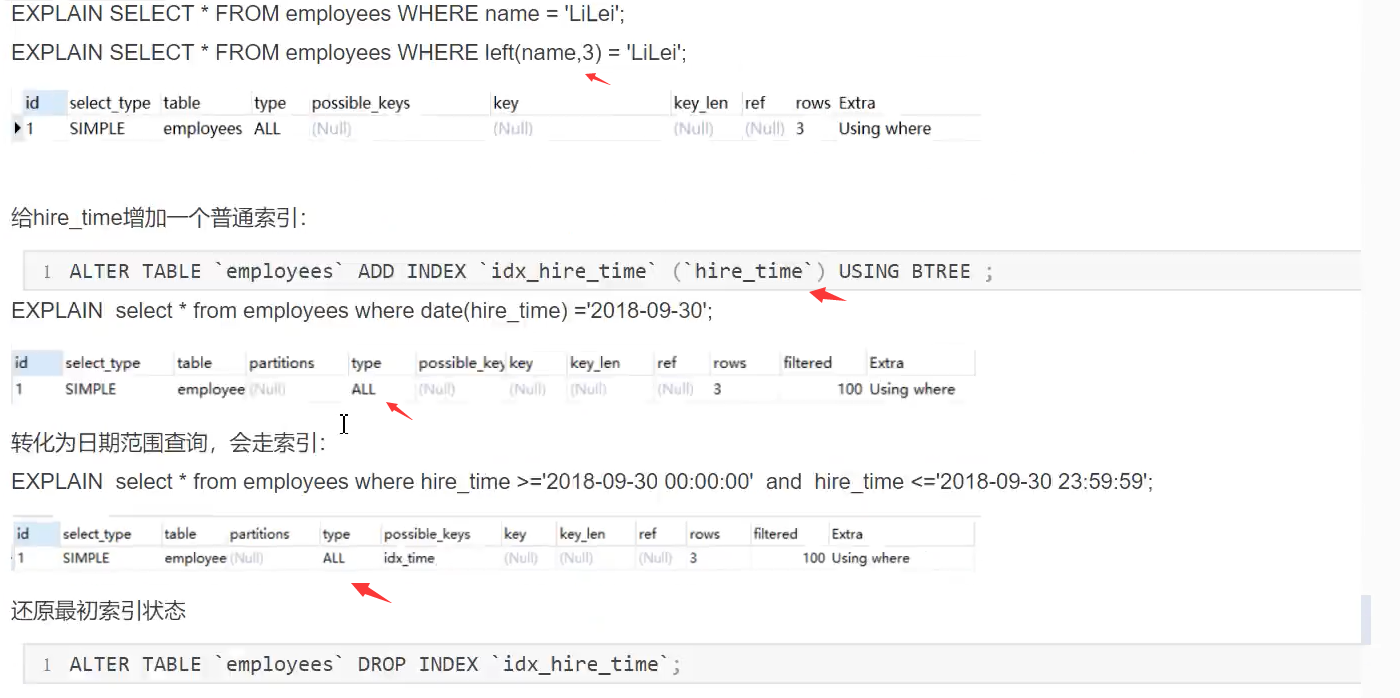
5、不能使用索引中范围右边的列

6、尽量使用覆盖索引

7、不使用!=、<>

8、不使用 is null、is not null

9、通配符%不应放在开头




