
一、HashMap底层原理存储原理详解
1、键不可重复、值可以重复;底层哈希表;线程不安全;运行key值为null,value也可以为null。
2、为什么HashMap底层JDK1.8后是:数组+链表+红黑树?
数组:ArrayList是最常用的 List(继承于Collection)实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要将已经有数组的数据复制到新的存储空间中。当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
链表:LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
红黑树:红黑树的查询效率高于链表,因此当链表长度为8时转化为红黑树结构;为什么查询快?(维护了树的特性,依赖于左、中、右三个节点,对应的大小为:小、中、大。当去查询一个节点时,会先去和根节点(中节点)进行比较,比它大,则和右节点进行比较,直到找到相同的,比它小则和左节点进行比较,直到找到相同的);为什么链表阈值为8?(小于8,链表效率大于红黑树,大于8,链表效率小于红黑树);为什么先是链表再是红黑树?(因为链表插入比红黑树快,红黑树在插入的时候需要去维护树结构,满足左中右的小中大,过程中会进行左旋或右旋,所以插入慢,所以先是链表)。
3、结论:
数组:查询快、插入删除慢,有序;
链表:查询慢、插入删除快,无序;
红黑树:查询快于链表、慢于数组,插入删除快于数组、慢于链表。二、HashMap哈希算法详解
1、哈希算法(也叫散列),就是把任意长度值(key)通过哈希算法变换成固定长度的key(地址),通过这个地址进行访问的数据结构;它通过关键码值映射到表中一个位置来访问记录,以加快查找的速度。
2、hashcode:通过字符串(key)算出它的Ascall码,进行mod(取模,计算出所设定数组大小的下标),算出哈希表中的下标。
3、哈希算法幂等性:相同的key,无论编译多少次,它的hash值一定是固定不变的同一个值三、哈希冲突产生的原因详解
1、不同的字符串(key),计算出来的hash值相同(即数组的下标相同),解决hash冲突的方法就是通过链表(hash冲突时,调用equal()方法,如果key相同,返回true,覆盖原来的值;如果key不同,返回false,在链表的下一个节点新存储这个值)四、HashMap底层存储数据结构详解
JDK1.8之前:数组+链表
JDK1.8之后:数组+链表+红黑树
1、数组:每个元素存储key、value、hash、next,key和value对应键和值,hash对应key通过hash算法计算得到的hash值,next用来指向数组中有相同下标的元素(分析:假如数组下标为4的位置现在已经有值了,现在又来存一个值,它的key通过hash算法计算出来的下标也为4,那么这个值会替换之前那个值,用next指向所替换的那个值,这时就形成了一个链表结构.如下图;当然查询时候也通过key计算出hash值,hash值取模得到下标,找到位置比较hash值是否相同,相同则返回值,不相同则去判断next为不为null,不为null说明为链表结构、然后再依次去判断每个节点和所查询的节点的hash值是否相同,如果存在返回值,不存在返回null。因此hash是查询作用,next是指向作用)。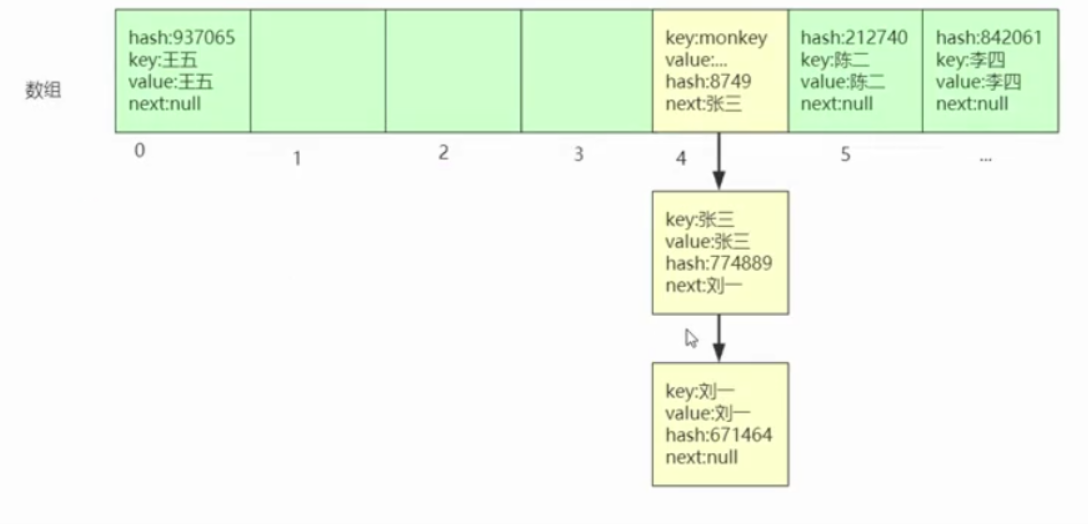
2、链表:单向链表和双向链表。
单向链表(在Java中用Node表示,通过next指向下一个节点。假如现在有三个节点,那么他们的指向关系为:
Node n = new Node("张三");
n.next = new Node("李四");
n.next.next = new Node("王五");
)。
双向链表(也是Node表示,除了通过next指向下一个节点,还通过pre指向上一个节点;因此每一个节点除了存取值以外,还包含next和pre节点的引用地址)五、HashMap在JDK8新增的红黑树详解
JDK8内部数据结构为数组+(链表 或 红黑树),通过key的hash值计算数据所在数组下标,多个key的hash相同或hash计算的数组下标相同,但是key值不同时,检查节点是否为树节点,是树节点则往树节点添加,如果是普通节点则往链表尾追加Entry,当链表长度大于8时,则将链表转为红黑树。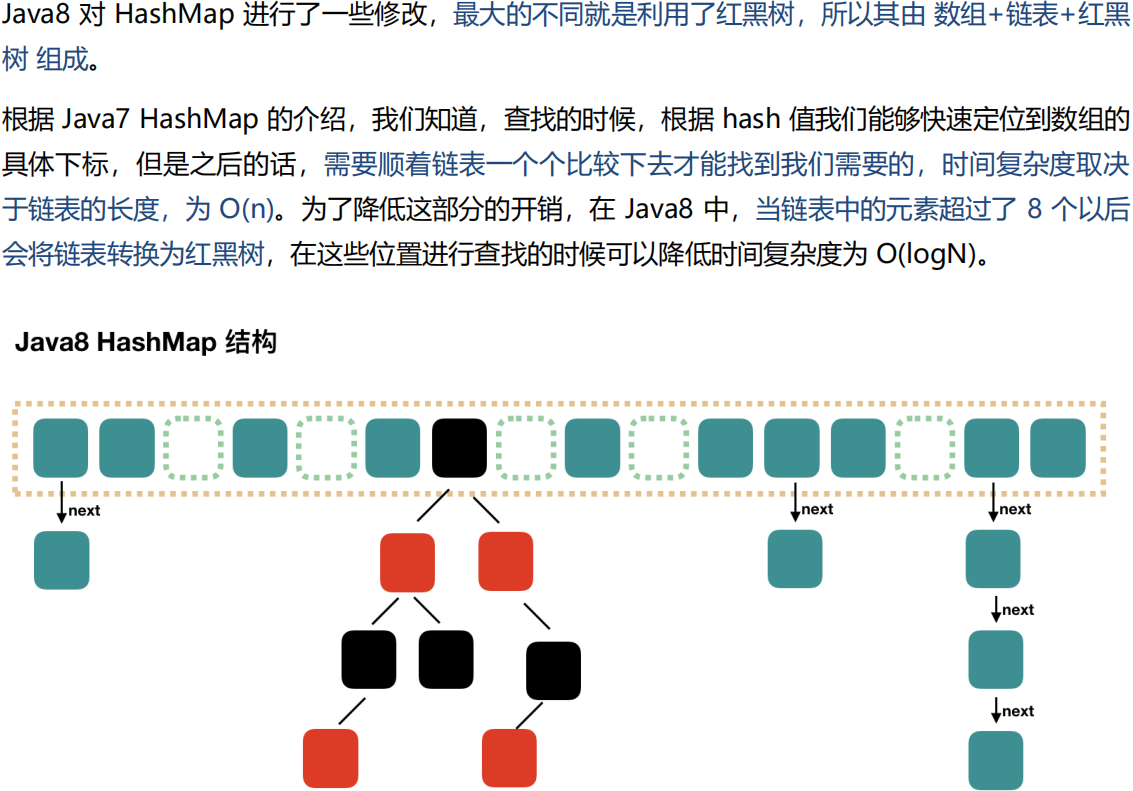
六、头插法和尾插法的优缺点是什么?
1、头插法:JDk1.8之前采用的方式。即链表的存储结构,当有相同下标的元素时,会替换之前那个元素,用next指向它。
2、尾插法:JDK1.8之后采用的方式。七、手写实现HashMap并性能测试
1、接口
public interface IMap<K,V> {
V put(K k,V v);
V get(K k);
int size();
interface Entry<K,V>{
K getKey();
V getValue();
}
}2、实现
public class HashMap<K,V> implements IMap<K,V> {
private Entry<K,V> table[] = null;
int size = 0;
public HashMap(){
table = new Entry[16];
}
/**
* 通过key进行hash算出hashcode
* 进行取模获取下标
* 去数组找到下标对应Entry对象
* 判断这个对象是否为空
* 如果为空 直接存储key value
* 如果不为空 采用链表
* 返回
* @param k
* @param v
* @return
*/
@Override
public V put(K k, V v) {
int index = hash(k);
Entry<K, V> entry = table[index];
if(entry == null){
table[index] = new Entry<>(k,v,index,null);
size++;
}else{//链表
table[index] = new Entry<>(k,v,index,entry);
}
return table[index].getValue();
}
private int hash(K k) {
int i = k.hashCode() % 16;
return i >=0 ? i:-i;
}
/**
* 通过key进行hash算出hashcode
* 进行取模获取下标
* 去数组找到下标对应Entry对象
* 查询的key和对象进行比较是否相等
* 如果不相等 判断next是否为空
* 如果不为空 比较他们hash是否相等
* 如果相等直接返回
* 如果不相等 再判断next是否为空 直到空或者相等为止
* 然后返回
* @return
*/
@Override
public V get(K k) {
if(size == 0){
return null;
}
int index = hash(k);
Entry<K, V> entry =findValue(k,table[index]);
return entry==null?null:entry.getValue();
}
private Entry findValue(K k, Entry<K,V> entry) {
if(k.equals(entry.getKey()) || k == entry.getKey()){
return entry;
}else{
if(entry.next!=null){
return findValue(k,entry.next);
}
}
return null;
}
@Override
public int size() {
return size;
}
class Entry<K,V> implements IMap.Entry<K,V>{
K k;
V v;
int hash;
Entry<K,V> next;
public Entry(K k, V v, int hash, Entry<K, V> next) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}八、记一次生产环境HashMap导致cpu100%的问题
通过解读HashMap源码并结合实例可以发现,HashMap扩容导致死循环的主要原因在于扩容过程中使用*头插法*将oldTable中的单链表中的节点插入到newTable的单链表中,所以newTable中的单链表会倒置oldTable中的单链表。那么在多个线程同时扩容的情况下就可能导致扩容后的HashMap中存在一个有环的单链表,从而导致后续执行get操作的时候,会触发死循环,引起CPU的100%问题。所以一定要避免在并发环境下使用HashMap。九、集合关系图
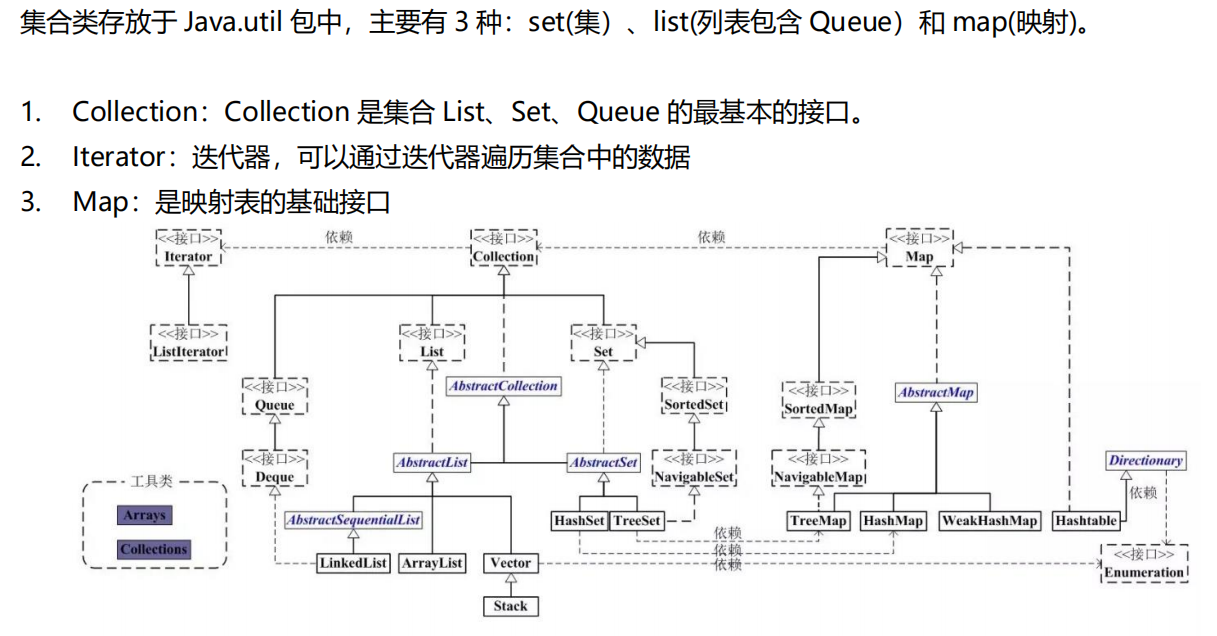
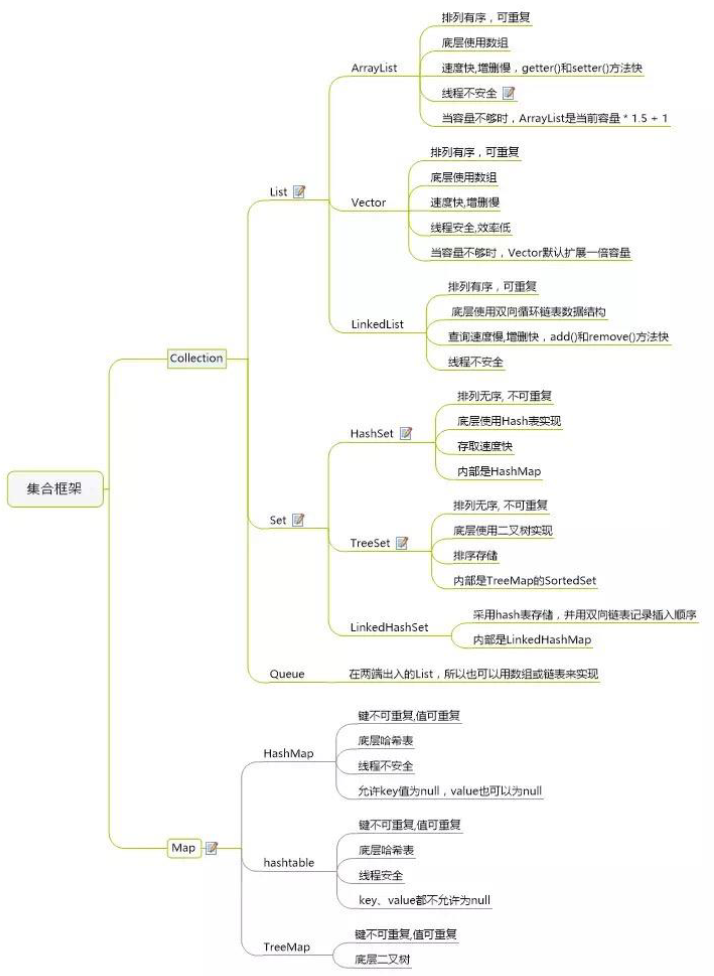
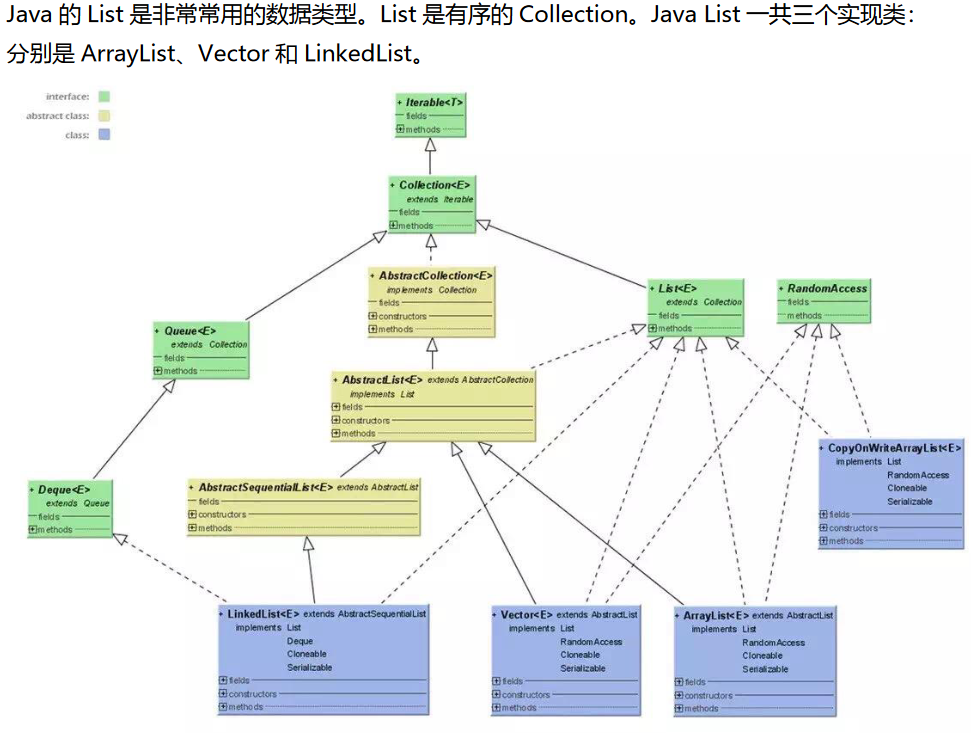
1、List(ArrayList、Vector 和 LinkedList。)
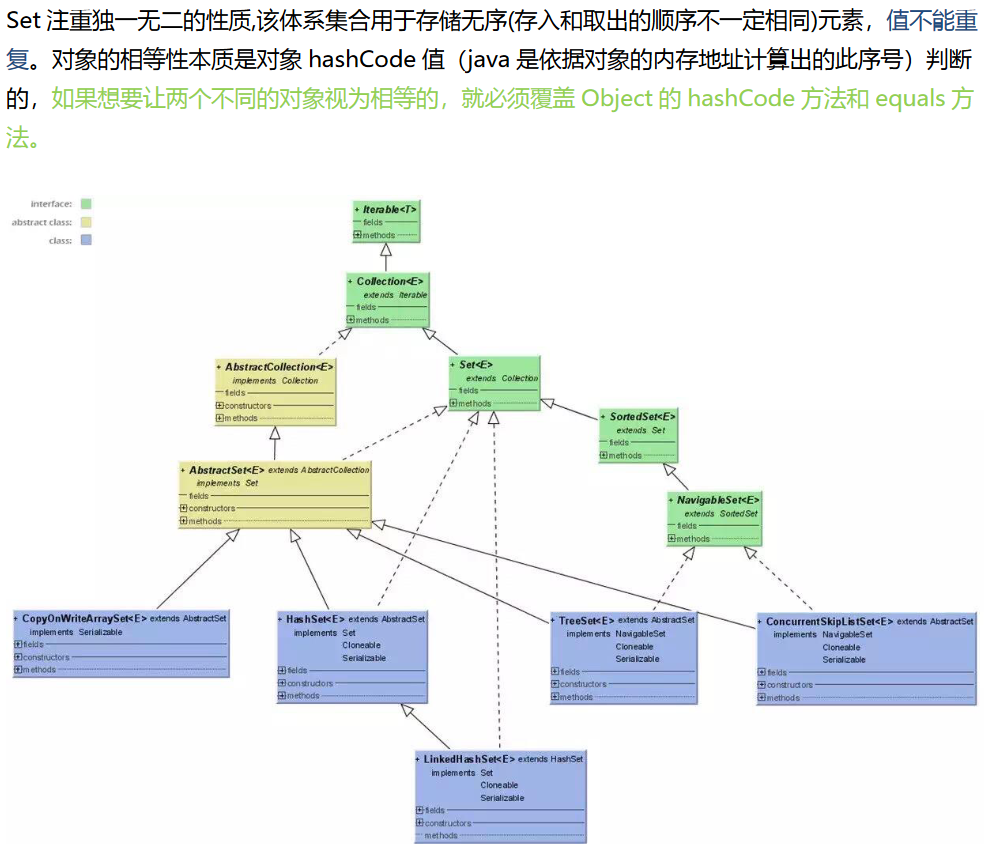
2、Set(HashSet、LinkHashSet、TreeSet)
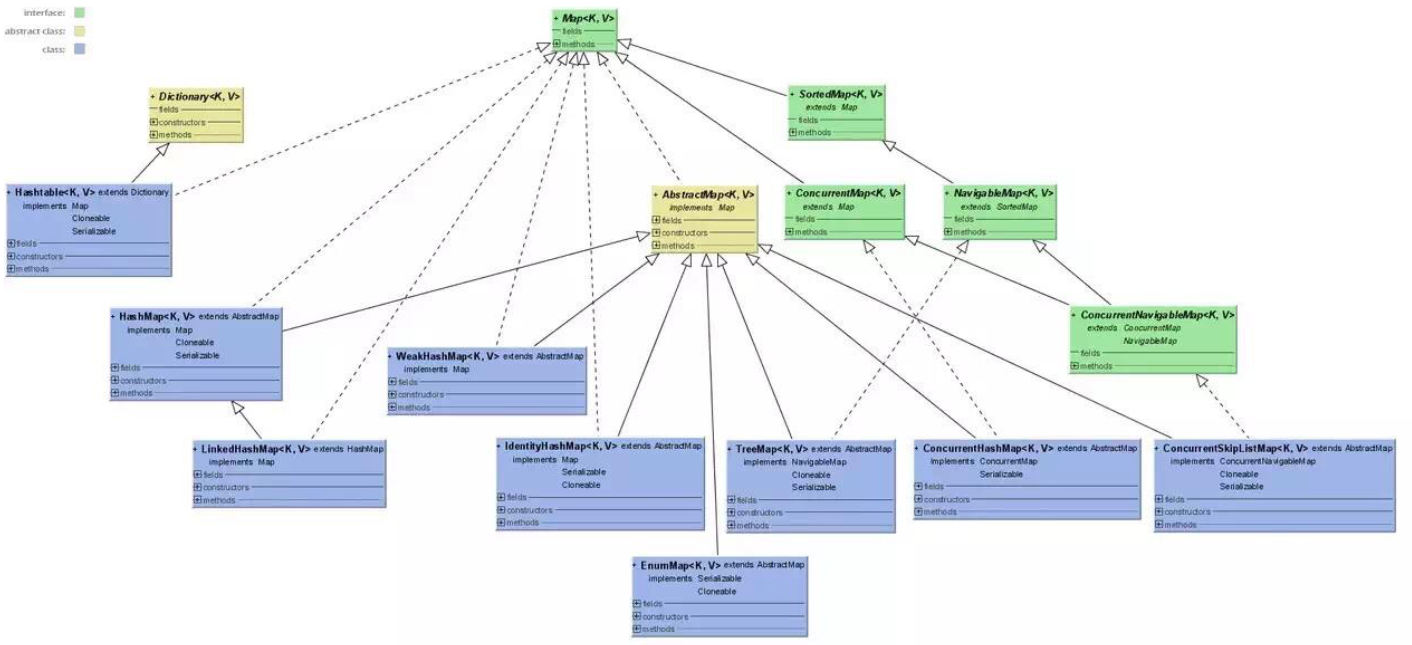
3、Map(HashMap、LinkHashMap、HashTable、TreeMap)
提取码:3u3m


